Teams often kickstart A/B testing programs with a handful of tests backed by a straightforward process and a shared doc.
That works well enough at low volume.
Early wins increase confidence, more teams want access to testing, and leadership begins looking at experimentation as a lever for growth rather than a side initiative.
As test velocity increases, the parts of the program that were never designed for scale begin to break down, from prioritization and governance to data consistency and experiment quality.
This article covers the pitfalls that show up specifically while you try to scale testing programs, why they’re easy to miss, and what programs that grow without breaking tend to do differently.
What does it mean to scale an A/B testing program?
Scaling a program means a few different things, depending on where it sits.
For some teams, it means increasing test velocity, moving from four or five tests a month to twenty or more.
For others, it means expanding testing beyond a single function (say, the marketing or web team) and bringing other teams like product, pricing, or customer success into the mix as well.
In more mature organizations, scaling also means building a culture where experimentation becomes part of how decisions are made across departments.
What all of these have in common is that they introduce complexity that a small, single-team setup was never built to handle.
Why scaling A/B testing programs often fails
A lack of proper infrastructure combined with low governance is usually what prevents experimentation programs from truly growing.
Some common issues include:
Tracking test ideas in scattered spreadsheets with no centralized workflow.
Using a single experimentation platform account without proper access controls or governance.
Storing test results in isolated documents or inboxes makes past learnings difficult to discover or reuse.
Allowing different teams to follow different testing standards and processes.
Measuring success using inconsistent metrics or significance thresholds across teams.
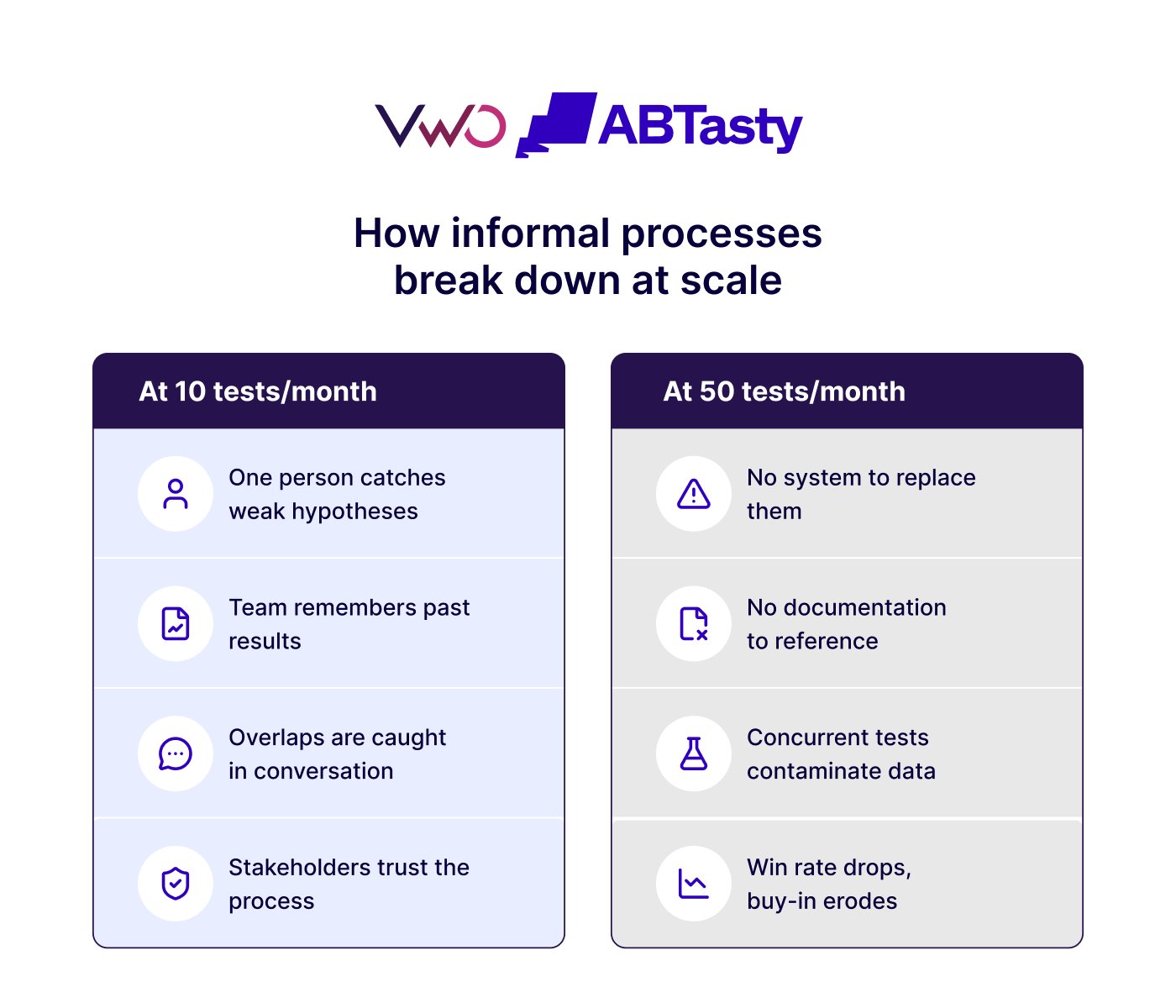
As more teams begin experimenting simultaneously, these gaps compound quickly, making the program increasingly difficult to manage effectively.
Then there’s the leadership problem. Rafael Damasceno, a leading CRO practitioner, says,
If leadership doesn’t demand an experimentation mindset from all departments, very often the CRO team will be limited to gains in specific areas of the customer journey.
Areas where experimentation can shift business outcomes, such as pricing, product features, and onboarding flows, remain out of reach.
Most common pitfalls in scaling A/B testing programs
1. Stopping tests early to keep up with the testing schedule
As you scale A/B testing programs, testing velocity quickly becomes a goal in itself. That pressure often leads teams to call tests sooner than the data warrants.
A test looks like it’s trending positive after a week, the team is behind on its experimentation targets, and someone makes the call to end it early and ship the winner.
However, early results can often be misleading.
Conversion rates fluctuate, especially in the first few days of a test, and what looks like a clear winner at day seven can flatten or reverse by day fourteen.
This is when teams start noticing that the “winners” they shipped are not really moving the downstream metrics, which can impact the trust and confidence people have in the overall process.
2. No shared test repository
Running tests without building on what they reveal is one of the most common ways scaling programs stagnate.
When learnings from one test don’t carry over to the next, whether that’s a hypothesis, an audience insight, or a failed variation, teams end up making the same mistakes and missing opportunities to compound their wins.
One team runs a checkout flow test in Q1 and uncovers a key friction point.
By Q3, another team is testing something nearly identical with no knowledge of what was already learned.
The insight never traveled, and the program never matured beyond a collection of one-off experiments.
3. Inconsistent measurement standards
Different teams using different success metrics, significance thresholds, and test durations will produce results that can’t be compared or aggregated.
Marketing might call a test a winner at 80% confidence, while the product team holds out for 95%.
Neither is wrong in isolation, but without shared standards, decision-making becomes inconsistent and difficult to trust at scale.
Setting expectations early on about measurement standards helps avoid inconsistencies later as the testing program scales.
4. Overlapping tests are contaminating each other’s results
When multiple teams run tests on the same pages or audience segments simultaneously, users can end up in more than one experiment at a time.
This creates interaction effects that distort results in ways that are genuinely hard to trace.
For example, a pricing page test and a navigation test running simultaneously, each drawing from the same visitor pool, will produce data neither team can fully trust.
At low volume, this rarely happens. But once multiple teams begin running concurrent experiments across functions, it can become a recurring data integrity problem.
Teams see unexpected results, they struggle to explain the variance, and often blame the tool rather than the test design itself.
5. Scaling scope without scaling tooling
Many teams start with a platform that works well for a single user or a small group.
Problems emerge as the program expands and more teams need to run experiments simultaneously.
Tools that were sufficient at a smaller scale often lack the governance and coordination features needed for broader adoption, such as role-based permissions, workflow controls, centralized visibility, or safeguards to prevent conflicting tests from running on the same page.
She described the shift from a scrappy single-team program to one that spans functions, highlighting how the operational overhead of keeping it running without proper infrastructure is significant.
Pro Tip!
Establish role-based access controls early as your experimentation program expands across teams. VWO’s permissions framework helps organizations scale experimentation in a controlled way by assigning access based on responsibilities, reducing the risk of conflicting changes, unauthorized edits, and workflow bottlenecks as more stakeholders begin running experiments.
How to avoid these A/B testing pitfalls
1. Lock in test parameters before launch, not during
Define the test parameters, such as minimum sample size, expected runtime, and primary metric, before a test goes live, and do not tinker with them once results start coming in.
When teams treat these parameters as launch conditions rather than guidelines, the pressure to call tests early disappears on its own.
VWO’s statistical engine supports this by helping teams calculate significance thresholds up front and flagging underperforming variations before they further skew results.
An experimentation charter might sound too much. In practice, it’s an internal document that removes misinterpretation that slows down every test debrief.
2. Build a test repository everyone actually writes to
A shared repository of every test, its hypothesis, results, and conclusions needs to exist and be maintained for everyone’s consumption.
VWO Plan is built for this kind of cross-team visibility, so what one team learns doesn’t stay buried in a dashboard only they can access.
3. Make mutual exclusivity a default
Audience overlap between simultaneous tests should be handled at the configuration stage.
The roles and permissions also give teams visibility into what else is running before they launch.
This helps catch conflicts early, before they show up as unexplained variance in results.
4. Connect the test backlog to business goals
This is where leadership involvement makes the biggest difference.
Teams typically need to build that trust first by running smaller, faster tests that demonstrate the value of experimentation through tangible results.
Starting with quick wins makes it easier to get buy-in for bigger, more complex experiments over time.
Scaling A/B testing without falling into common traps
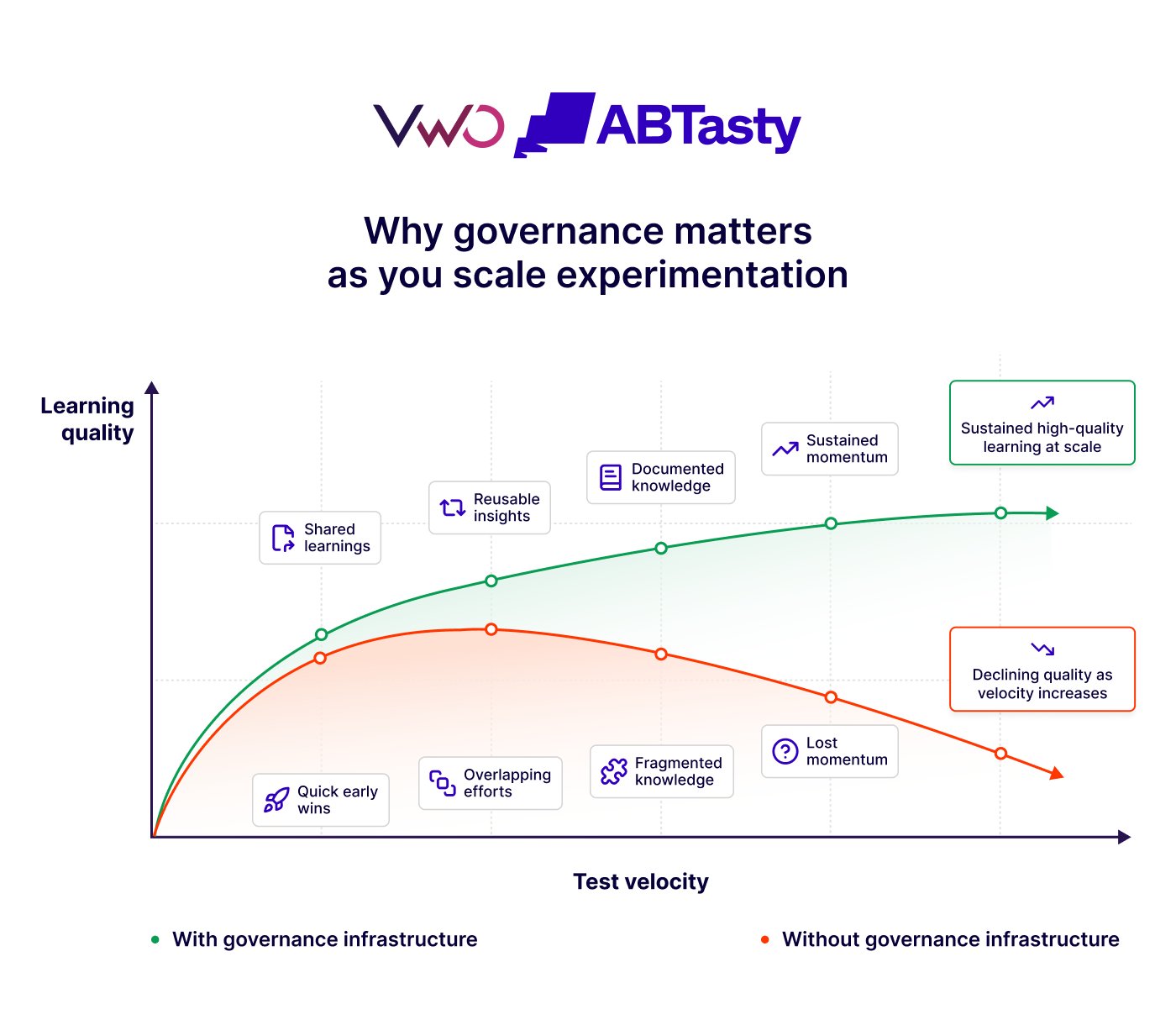
Scaling experimentation is not always about test volume or speeding things up.
Instead, what matters more is whether or not you have built the structure to support these things.
The organizations that scale successfully build shared standards, visibility across teams, and the operational structure needed to keep experiments reliable as adoption grows.
Platforms like VWO support this with capabilities such as role-based governance, centralized planning, mutually exclusive test groups, and more.
Schedule a demo to see how a structured experimentation setup can help you scale your testing program with confidence.
Frequently asked questions (FAQs)
Q1. What is the biggest challenge in scaling A/B testing?
Getting the entire organization to treat experimentation as a shared function rather than one team’s tool is a critical challenge while implementing A/B testing at scale. Without active leadership involvement, even the most capable teams end up running safe, low-impact tests.
Q2. How many tests should you run when trying to scale your A/B testing program?
Although there’s no universal number, the right test volume depends on how much traffic you have to work with. Running too many tests at once splits your audience across multiple experiments, which thins out your sample sizes and makes it harder to reach statistical significance. It results in longer test times or produces unreliable results.
Q3. Why do A/B tests fail at scale?
A/B tests tend to fail at scale because the program grows faster than the process does. Early calls, inconsistent metrics, overlapping audiences, and a backlog full of low-stakes tests are symptoms of a platform that wasn’t built for the volume.
Hi, there! I’m an Associate Manager of Content at VWO with 6 years of experience in B2B and B2C marketing. I work across blogs, SEO, thought leadership, newsletters, landing pages, and a video podcast I built and manage from scratch. At VWO, I’ve gained expertise in CRO, experimentation, user behavior research, and personalization, creating content that makes complex ideas clear and actionable. Outside of work, I enjoy experimenting with memes and short-form video on Instagram.
Uncover hidden visitor insights to improve their website journey
One of our representatives will get in touch with you shortly.
Awesome! Your meeting is confirmed for at
Thank you, for sharing your details.
-
, you're all set to experience the VWO demo.
I can't wait to meet you on at
Account Executive
, thank you for sharing the details. Your dedicated VWO representative, will be in touch shortly to set up a time for this demo.
We're satisfied and glad we picked VWO. We're getting the ROI from our experiments.
Christoffer Kjellberg
CRO Manager
VWO has been so helpful in our optimization efforts. Testing opportunities are endless and it has allowed us to easily identify, set up, and run multiple tests at a time.
Elizabeth Levitan
Digital Optimization Specialist
As the project manager for our experimentation process, I love how the functionality of VWO allows us to get up and going quickly but also gives us the flexibility to be more complex with our testing.
Tara Rowe
Marketing Technology Manager
You don't need a website development background to make VWO work for you. The VWO support team is amazing
Elizabeth Romanski
Consumer Marketing & Analytics Manager
Trusted by thousands of leading brands
Awesome! Your meeting is confirmed for at
Thank you, for sharing your details.
Your Roadmap to Better Results
1:1 Demo customized to your industry and optimization goals.
Feature deep-dive into the user behaviour tools you need most.
No-pressure advice on the best path forward for your team.