

Your peer comes over to you with a test idea. They want it placed in the roadmap and prioritized accordingly. ‘No problem’, you reply. You discuss the concept, translate it into a rough wireframe on the spot, and get their approval on the idea. Your peer says, ‘Great. So what are we thinking, can we launch this tomorrow?’
How often have conversations like this taken place where someone doesn’t fully understand CRO, and what goes into running an experiment? In my experience, it happens a lot more often than you think. Even those who have a crystal clear process don’t necessarily know how BEST to build and run an A/B test. Sure, physically launching a test is as easy as clicking a big blue button, which says ‘Launch Test,’ but there is a lot more that should go behind the scenes of building the test.
Download Free: A/B Testing Guide

Data capture and analysis
In this article, I’m going to go in-depth to explain exactly what is involved in a single A/B test, and what can be done to streamline the process of test building.
The ‘test’ actually starts before any ideas even come to the table. Why? Because your ideas should be grounded in some form of data.

Why is this important in an A/B test? When you’re building priorities for A/B tests, those with some kind of data should always be prioritized over those that do not. All tests I’ve won have had some version of data feeding into it, and to date, I have not won a test that went off simply on a ‘gut feel’ or instinct. Your tests’ win rate will be far higher if you run tests grounded in some form of data to influence test build.
In each job where I started as a CRO professional, I rarely ran a test in the first month. It took me a few weeks to immerse myself into all available data, and combine that data with my observations to identify tangible things to test.
One example of this was when I was looking at a site from the outside in, I had a number of ideas for things which I thought made sense to test. After looking at the data, I realized some of my ideas, while valid, would not be as impactful as testing into other concepts. Notably, one site I was testing into had an absurd amount of click action on a specific element that I would’ve never thought would happen. Once I realized this was how users were interacting with our site, I heavily prioritized a test to capture some of the attention paid on this particular element to shift attention away from that element.
Without spending the time digging deeper into the data, I would’ve missed this obvious prioritization of a test. And it’s not always easy spending time in data collection. Data collection can be quite tedious and time-consuming, and sometimes you may not have tangible next steps as a result of your collection. But try to identify ways to focus your data collection based on specific tests, concepts, or problems you’re trying to solve.
One way is to utilize help from other teams, such as UX and analytics. Sometimes, you can identify test ideas simply by looking at analytics and heatmaps. But your UX team can help you further in your data collection. Talk to them about the data you have and the problem you’re trying to solve. The UX team can help by providing different test executions or conducting user surveys to help you get closer to a more data-driven test.
Here is an incredible webinar to dive deeper into the topic of hypothesis generation for a test.
Shiva Says: Run tests that help with not only finding a test winner but can instruct future iterations of testing. Test to learn, not to win. If you run a test where you learn, that is data in itself to focus on for your next test – compound your learnings to improve your chances of hitting test winners.
Test development

In my test prioritization framework, I always consider how much of a lift the test is to the development teams. I handle some tests on my own with my javascript/css knowledge. For other tests, I have test concepts but need to discuss with the developers to see if it’s even something we could potentially run. And there are many in the middle, where based on execution, we scale the test complexity based on engineer bandwidth.
We can run certain tests client-side, with minimal changes made on the page. Other tests require extensive development, even when running them client-side. But therein lies the challenge – with most tests, there will always be some amount of development required. The bigger challenge comes from having to prioritize those bigger tests within development cycles, and sequencing in tests so that there isn’t a gap in experiments running due to developer limitations.
The secret for me is first, prioritizing a bulk of lower lift tests so that there is a queue of tests built up. Then, prioritizing 2-3 bigger tests so that the developers have more time to sequence those tests in. Then repeating this process so that you have a queue of tests ready to go, and while the developers are working on bigger lift tests, you’ll have a test running in the background.
The other thing you can do is take a look at the hypothesis of what you’re testing and identify other ways to learn more about the hypothesis without fully committing a ton of resources into the execution. Said differently – test it a different way, learn from those results, THEN use that as data to prioritize (or deprioritize) the next iteration.
This is something which was interesting and humbling to learn. Out of the many tests I’ve run, there is really no correlation between dev lift and increased percent chance of winning. I’ve run tests that have taken 1.5 months to code up, only to have them lose. I’ve also run tests that were simple rearrangement tests, which took me 10 minutes to code up and have seen statistically significant winners. So to assume that more development is equal to a higher chance of winning isn’t really correct. Sometimes, it’s okay to reconsider the execution of the test to reduce the lift on the engineering team.
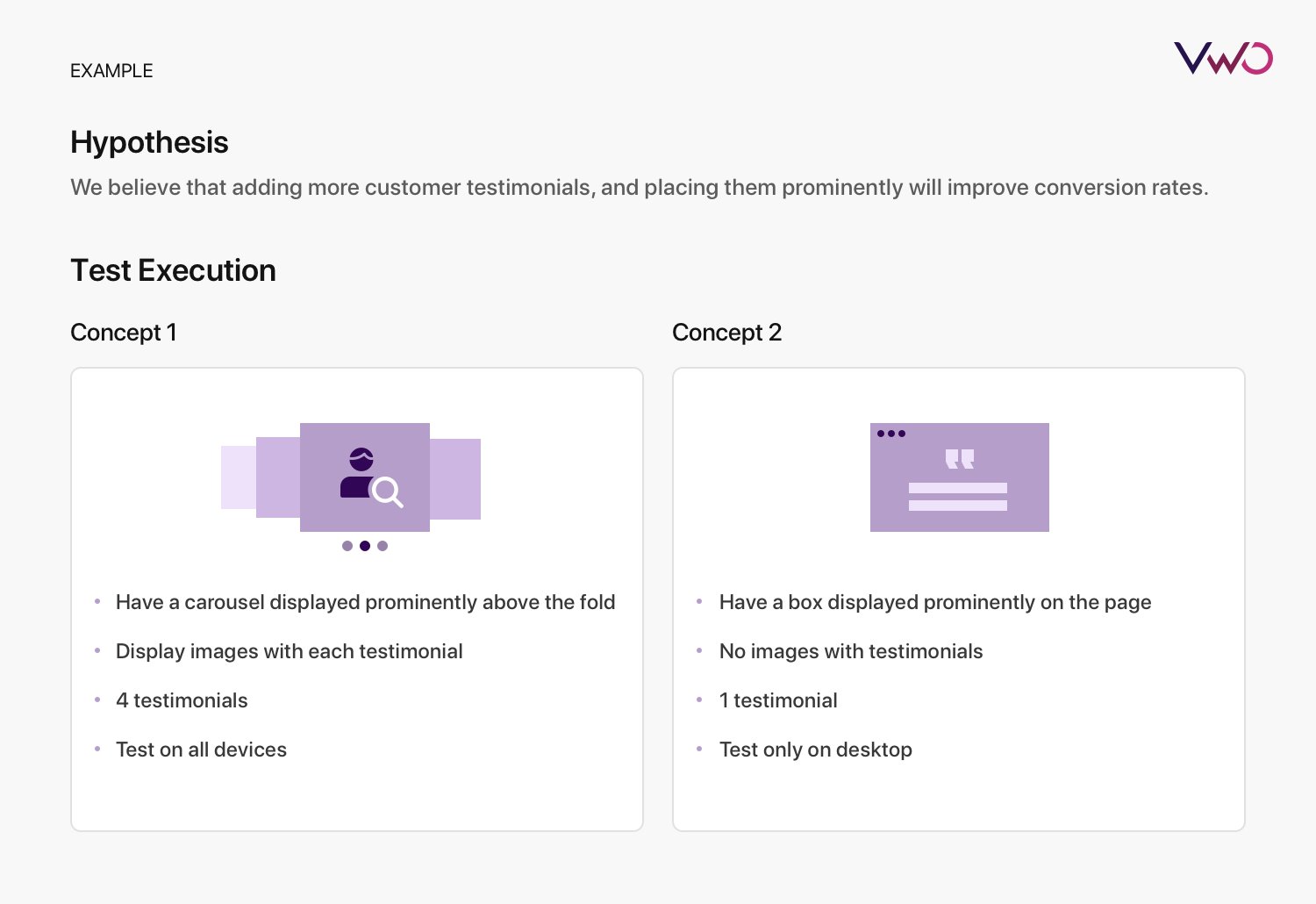
In the above example, concept 1 would likely take longer due to development lift to build a carousel, while in concept 2, you may even be able to get away with minimal HTML/Javascript. By also narrowing the scope to desktop, you don’t have to worry as much about how the box could break in a responsive design, to enable you to rely less on developers.
It’s definitely possible that concept 1 is a far better test in terms of execution than concept 2. However, you can use heatmap data, as well as take a look at engagement with the page and CVR to see if this is a concept worth pulling more resources into!
This isn’t a hardened rule, where you should do your best to reduce execution to accelerate time to launch the test. But in a world of prioritizing engineering resources for experiments, this is one way to help reduce that lift and help you accelerate testing velocity and accelerate learning gathering.
Collaboration
Experimentation is not a silo. Experimentation affects all channels and should be influenced by those functional leaders.
It’s a two-way street, where they both work hand in hand with each other. If you’re building a test and not looping in all the relevant people, you could run into many shortcomings.
I learned one of these shortcomings the hard way. I was running tests without getting approval from the design team, and as a proxy of it, some tests were not following the design standards. This wasn’t a problem until I hit my first test winner, and pushed it to the dev team to hard code. We couldn’t go live with it because while the test was a statistically significant winner, it broke some brand and design standards.
After realizing this mistake, we had to build in some additional approvals from the brand and design teams to ensure that moving forward, we could push any test to live if it was a winner. Building this process actually created some great ripple effects:
- We were aware of some of the things the design and brand team were working on for additional test ideas.
- Getting design feedback on some tests helped create more powerful, impactful, and honestly, better tests.
- This shifted some of the work off my team from a design perspective and allowed our experts (designers) to design better looking/functioning tests.
- By opening our roadmap to more teams, we were able to share our test results with other teams to help influence their programs.
- The time to push winning tests to production reduced dramatically since brand and design already approved everything.
- Because the designers were involved in the first version, they were able to help rapidly create iterations of the winning variations.
Collaboration with these teams doesn’t stop with just test approval, though. And collaboration isn’t limited simply to the teams directly involved with experiments. Customer service, accounting/finance, sales, and other functions can all help contribute to experimentation. They all interact with the customers and the business in different and unique ways, and can offer valuable perspectives to your experimentation program.
- I schedule regular syncs with those who need to be looped into experiments (e.g., engineer project managers). This is more preventative, so they’re aware of the tests we’re running, and we can ensure no tests will break or interfere with any rollouts or changes.
- I try to schedule a brainstorming session every few months with those whose feedback can be beneficial. I share past test results with them and discuss new test ideas that they may have.
Once you’ve got all the right ideas from brainstorms, it benefits you the most to keep your experimentation program an open book. It’s a great benefit to have a roadmap tool which consolidates your test hypotheses, notes, screenshots, and results in a single place for anyone within the company to access – doing so keeps the flow of communication open! Experimentation should never be a black box that only a select few have the key to. That only limits the reach of experimentation and keeps CRO as a silo.
Shiva Says: Being a CRO manager involves a certain level of politics. What I mean is that there is give and take, interactions with other functions, etc. Consider improving relationships with key stakeholders, and identify ways to work on a shared, collective approach to experimentation rather than a client/vendor relationship. E.g. “How can we work together to help you collect data and identify the best user experience” (Good) vs. “Ok Brand Manager, sign off on this test” (Bad).
Download Free: A/B Testing Guide
Quality assurance

It’s easy to launch a test. Press the big shiny blue button which says “Start”. But, you wouldn’t roll out any kind of code live to production without a thorough QA process. Engineering teams have dedicated resources specifically for QA. Your experiment code needs to have a high level of scrutiny as well.
What are the risks? Breaking the site, obviously. But another potential risk is running an experiment which you believe is doing something to the site and interpreting those results. For example, let’s say you run an experiment, which is adding testimonials to a page. The experiment code breaks, and the testimonial shows up broken and gives your page a very bad look. You look at the results and see a -6% CVR. You may interpret the results as ‘customer testimonials may not work for us’, which is obviously an incorrect assumption! (By the way, this is an actual thing which happened to me – thankfully, I did a deeper dive into the experiment to identify that the code in fact broke).
This is also why I preach collaboration – weekly syncs with engineering teams help mitigate a lot of such risks. You’ll be aware of their code rollouts, and they’ll be aware of your experiments, to avoid potential conflict between these lines of code interacting with each other.
There is another source of potential conflict – interaction effects. Said differently – experiments running on top of each other. There has to be a regular check of not only launching tests, so they don’t break the site, but launching tests intelligently, so they don’t interact with each other. There are ways to overcome this (e.g., mutual exclusion), but these strategies can sometimes increase the time to test due to the lower amount of traffic going into your experiments, or needing to delay an experiment launch due to the interaction effects.
Shiva Says: Set up a weekly reminder to QA your experiments. Block off an hour and just review your live experiments and ensure they’re all working the way they need to, and NOT interacting with other pages/experiments.
Prioritizing Test Ideas

Going back to the first example, where a coworker is looking to launch a test ASAP – it’s not always in the best interest to immediately run a test once it’s ready to go. In fact, there are tons of articles on ways to consider prioritization of tests based on frameworks.
Why? Because experimentation at its core means there will be times that you lose. And the cost of losing should be considered given the inputs required in creating a test. Consider everything I’ve mentioned above, and recognize that there is a lot of hard work going into each and every test. If you are running tests haphazardly without considering implications, you’re not only going to find more losers than winners, but you will not be utilizing your resource pool for maximum efficiency. In a way, you need to optimize not only your website, but the way resources feed into each experiment!
I won’t go into the framework I use personally, because it simply just depends on your organization. For example, an organization with limited development capacity needs to prioritize engineering lift much greater than another organization with dedicated developers for experimentation. I am currently running optimization programs across multiple brands, and each brand has a different prioritization strategy.
However, a few broad things to consider as you work through prioritizing your tests are:
- Disruption of test (how much of an impact it could have to revenue)
- Engineering lift
- Quality of learning from tests
Just because you CAN run a test, doesn’t mean you SHOULD. There are right times to run specific tests, and making sure that you’re considering all inputs before running a test will help you in the long run.
Shiva Says: A prioritization framework works incredibly well. However, be open to having fluid prioritization. When you test to learn, each test will provide data for the next set of tests. If you have a static prioritization framework where you run tests 1, 2, 3, 4, 5, and 6 (in that order), that could work fine. But, if when you run test 1, you get data that tells you that test #3 may not be successful, you should consider deprioritizing test #3 in favor of 4, 5, and 6.
Key takeaways
- Collaboration is important, so try to set up processes to ensure optimal collaboration across the right teams.
- Telling too many people about a test is far better than not telling enough people.
- Test prioritization is important but should be fluid based on UX priorities, engineering resources, and learnings from previous tests.
- Don’t cut corners with QA – establish processes and follow them.
- Dev lift based on a test should not be static – you should be able to scale up and down the dev lift based on the hypothesis being tested and the subsequent test design. Use this to your advantage to learn instead of using more dev resources on a high lift test.
- Communicate how much of a lift a test may be – highlight blockers to launching tests, so stakeholders can start to understand what is involved in launching a test and help advocate for more resources to get the required tasks done.
Categories:





















