

Haley is the founder of Chirpy and specializes in user research-based experimentation.
Running experimentation programs is an art and a science. I say it all the time. Programs should have some level of rigor – meaning systems, processes, and procedures. It’s not something to take lightly. Believing that anyone can start a program tomorrow with minimal preparation and planning is a mistake. Unfortunately, though, that happens all the time. It leads to lots of money, time, and effort wasted – unsurprisingly. This leads me to the topic of preparation.
If you want to be serious about experimentation and level up how competitive you are in the marketplace, you better be doing it well. You should assume your competitors are doing it well. So if this resonates with you, continue reading and I guarantee you’ll pick up a golden nugget or two to use immediately.

The unavoidable precursor to building an experimentation program that will make or break you: Pre-test calculations
Pre-test calculations. Ever heard of them? Have you done them? Does MDE or minimum detectable effect sound familiar? How about duration estimates or sample sizes? I hope you know what I’m talking about although I’d bet money that a large majority of you don’t – simply because of my own personal experience with clients.
Before you do anything related to experimentation, please see if you have enough data volume to do it. See if you’re able to test at all through pre-test calculations. By data volume, I mean visitors and conversions. Visitors can be whatever you typically use (e.g., sessions, users, MAUs, etc.). Conversions are from the primary metric you’re going to use in your tests. Know this:
- Not every business has enough data volume to do experimentation at any capacity.
- If you can do it, know that you don’t just pick your desired velocity out of thin air. It’s based on calculations.
The #1 culprit for ignoring one or both of these points: sales people. If you’re looking at buying any kind of tool, make sure this is part of the conversation. The minimum barrier to entry to have an experimentation program: enough data volume to run one test within eight or fewer weeks in one swimlane.
I covered this topic in detail a few months ago for Experiment Nation. Know that if you don’t understand this topic and do it from day one, it will haunt you and definitely cause undesired outcomes of some kind eventually. One other very important note: know if your testing tool (or the one you plan to use) is built based on fixed-horizon testing or sequential testing. This affects the calculations and how you run your program.
Step 1 (Post-precursor): Measurement & data quality
If you’ve cleared the pre-test calculations hurdle and you’ve confirmed that you do have enough data volume to test, the next hurdle to moving forward is measurement and data quality. You must know what you’re aiming at in this work; otherwise, you’ll flounder like a fish on a riverbank. Too many teams don’t know what they’re working toward – like form submissions, transactions, revenue, LTV, etc.
Understand what your primary, secondary, and tertiary metrics are for experimentation and the business as a whole. Understand it with complete clarity. Don’t allow for lingering confusion or uncertainty. Make sure everyone is on the same page.
Then, once you have that much, make sure you’re collecting that data in the right places and that you can trust it.
If measurement and/or data quality are disasters, just stop. Stop everything and devote all of your efforts toward getting it right. Think of experimentation as a pyramid. These two things are the foundational layers of the pyramid. If it cracks at any point in time, everything else will crumble on top of it. I promise.
I’ll say that I know these can be hard. Getting them right can take extra time. Maybe even more than a month or two. Getting them right is worth it though. I’ve seen issues come up six months or more after launching a program – only for everything to eventually come to a screeching halt. No one is happy at that point.
A note on what a primary metric should be…
This is a divisive topic among practitioners sometimes. I have a very firm stance on the matter, specifically when it comes to marketing teams and websites (not necessarily product teams and products).
Primary metrics should always be down-funnel metrics. Orders. Form submissions. MQLs. Revenue. LTV. SQLs. You get the idea. Some people say they should always be the action closest to the change you’re making or engagement metrics. Wrong. No. Nope. Incorrect. BS. Whoever tells you this should be the one to have to justify the program in six months or a year to the CMO or CEO of the company. They’ll be in the hot seat. DO NOT have a program full of tests focused on button clicks, click-throughs, pageviews, avg. session duration, exit rate, bounce rate, video views, and so on and so forth. That’s not going to justify the thousands or hundreds of thousands of dollars spent to do this work. Everyone wants to know their ROI and how the work impacted the bottom line. Button clicks aren’t going to do that.
I’m not saying don’t measure engagement metrics or higher-funnel metrics, but they should be secondary or tertiary metrics. Not primary ones. They add context to the story of a test. They’re not what tests are hinged on when the time comes to make a decision. Note, I’m also not saying there are never exceptions. Still evaluate tests on a case-by-case basis.
A word of advice: To those debating this topic amongst yourselves, I always tell teams to discuss the options and decide for themselves. Just make sure you come to a collective conclusion that everyone abides by moving forward.
Step 2: User research & ideation
At this point, you should (1) know you have enough data volume to test and (2) know what you’re measuring and that you’re collecting proper data that you can trust. So what’s next? It’s coming up with what to test. What are your test ideas? How are you going to generate them?
Guess what most teams do? They go off of gut feelings and a lot of “we think,” “we feel,” and “we believe.” That is far too subjective, and it’s a terrible way to run a program. That approach is not data-backed at all. It’s what practitioners call “spaghetti testing” AKA flinging stuff at the wall and hoping it sticks. Data-based conversations don’t involve much of that sort of language, and the data that’s needed comes from user research. I get asked what “research” means all the time.
Well, there are several methodologies that collect data including but not limited to analytics, polls, surveys, user testing, message testing, heatmaps, session recordings, card sorting, tree testing, customer journey mapping, personas, and many more. There are also several tools to help us complete each of these. I always say to start with one or two and work your way to other ones from there. That’s certainly better than nothing. Technically, I don’t really count analytics anymore because every company has analytics data these days. If you don’t have that, you likely have bigger fish to fry. If you do have it though, strive for one or two beyond that even (and don’t say “oh we’re good then”).
There is a methodology called heuristic evaluation. That’s when someone visually assesses an experience and develops insights based on their experience and expertise. There’s a time and a place for it but it’s not backed by “hard data” most of the time. It’s quite subjective and will be different to some extent depending on who completes it. Know your program shouldn’t be based on these types of insights.
I’m not going to cover how to do research in great detail here, but you can check out one of my VWO Webinars here where I talk more about CXL’s ResearchXL model.
Step 3: Prioritization
Once you have a list of test ideas, you can’t do them all at once. You need a strategic, logical way to create an action plan. This is where prioritization frameworks come into play. Many exist. I like one in particular: the PXL framework from CXL. Other common ones include PIE, ICE, or PILL. The PXL is the most objective in my opinion. It’s customizable and more robust (in a good way).
Other models are okay and better than nothing. If you have something and it’s working for you, great. Just have one and make sure everyone is using it! It saves you from dealing with extra chaos.
Step 4: Roadmapping
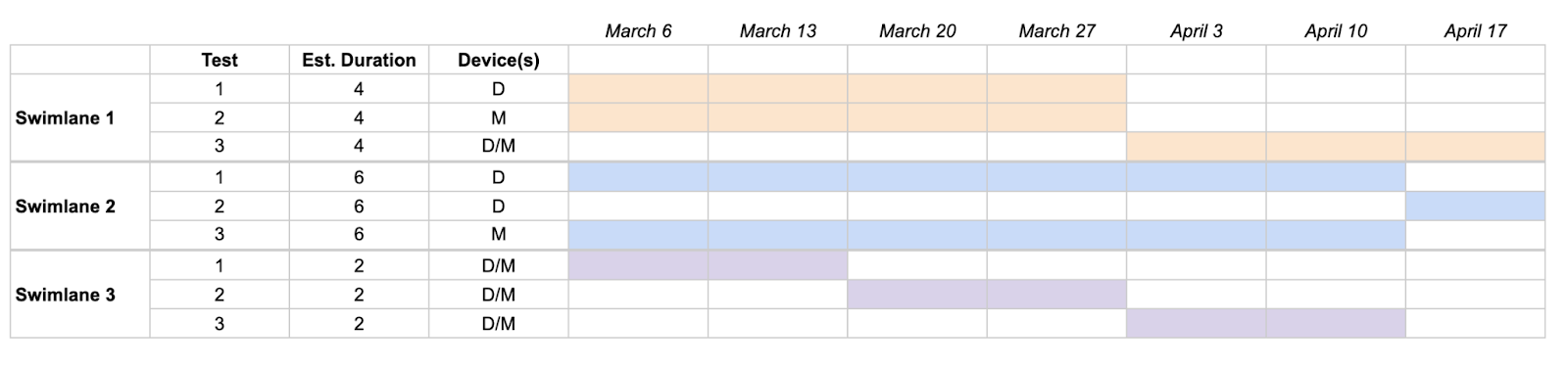
Roadmaps visually show you what’s running at any given time. Combine your prioritization and pre-test calculations and boom. You’ve got a roadmap. These are best done in Gantt charts. Add all of your swimlanes and tests with estimated durations, devices, and other helpful metadata. You’ll avoid unwanted overlap and unwanted interaction effects. It helps everyone plan much more effectively and efficiently. This will save you from more chaos.
Step 5 and beyond: Business as usual
Now that all of what we’ve covered is out the way, it’s business as usual. You have a test at hand that you’re going to run. You send it through the regular experiment workflow: mockup > design > development > QA > launch > monitor > conclude > analyze > share and archive > repeat.
Related topics: Program management & governance
Outside of individual tests, there are other topics for consideration in relation to an entire “program.” These include program management and governance. Here’s how I think about them in a very boiled-down way…
Program management: How are you going to organize and keep track of all of this work? Figure out what tools you’re going to use for tasks, data management, and communication. (I got that breakdown from Ben Labay, CEO of Speero.)
Governance: What roles and responsibilities does everyone have? A helpful way to determine this is to (1) choose a governance model and (2) complete a RASCI chart aligned with the governance model. Common governance models to investigate and consider: Individual, centralized, decentralized, center of excellence, testing council, and hybrids.
If you don’t nail down both of these with everything else, it’ll be additional chaos and you’ll pay for it every step of the way. Nail these down. It takes extra time, but it’s worth it. If you hack your way through things for a while, the consequences will catch up with you eventually. I promise. (Apparently, I have made quite a few promises here.)
Conclusion
You should feel a little (or a lot) more confident in what you can do to get started in experimentation or what you can do to level up your program that’s already running. Don’t feel it’s too hard or too easy. It’s usually somewhere in the middle. My biggest recommendation applicable to everything I’ve mentioned: Have a quarterback. Have someone that leads all of this work. It doesn’t have to be their full-time role, but someone should own it. That’s usually when I’ve seen the most success.
To wrap up, I hope you have an experimentation program full of rigor, results, and a little fun sprinkled in. At the end of the day, it’s fun and exciting work that can make a huge difference for a business.
If you would like to know more about how experimentation drives innovation and growth and is worth all the hype, watch my latest webinar with VWO.
Categories:





















